基于替换方法的无监督双语词典抽取
郭晋鹏 曹海龙


摘 要:
双语词典抽取任务是自然语言处理一个重要课题。本文基于替换方法重新训练词向量,使得词向量具有跨语言特性。本文主要研究了训练词典的获取方法,以及词向量共训练模型,在中英维基百科语料上进行实验。实验结果表明,按照确信度的方法选取训练词典,基于替换的方法得到的词向量跨语言性质较好,最终抽取的词典具有较高的准确率。
关键词:
双语词典抽取; 无监督; 替换方法
文章编号:
2095-2163(2021)03-0217-03 中图分类号:
TP391.1 文献标志码:A
【Abstract】Bilingual lexicon induction is an important task in natural language processing. This paper retrains the word vector based on the substitution method, so that the word embedding gets cross-language characteristics. This paper mainly studies the acquisition of training dictionary and the co-training model of word vector, and carries out experiments on the corpus of Chinese and English Wikipedia. The experimental results show that using the selected training dictionary according to the method of confidence, the word vector obtained by the method of substitution has a good cross-language property, and the dictionary extracted finally has a high accuracy.
【Key words】 bilingual lexicon induction; unsupervised learning; substitution method
0 引 言
在各种跨语言任务中,双语词典抽取是目前备受各方关注的研究课题。在多数跨语言自然语言处理任务,如机器翻译[1]、跨语言文本分类[2]、跨语言情感分析[3]中,跨语言词典都起着至关重要的作用。但是,进行跨语言词典抽取往往需要人工标注的跨语言知识,如平行语料或者人工标注的翻译词典等。但世界上大多数语言对之间的平行语料或者种子词典是十分匮乏的。因此,近年来学者们开始研究无监督跨语言词典抽取,旨在使得计算机能够在不借助跨语言知识的前提下即可得到跨语言信息,从而高效、自动地获取跨语言知识。无监督跨语言词典抽取都基于如下的一个基本假设:对于不同语言的基于分布式表示的词向量空间,都存在某种映射关系,可以使其投影到相同的空间中,并且具有相同语义的单词在这个空间中的距离会彼此接近。
目前,无监督跨语言词典抽取方法已经取得了很大突破,典型工作有:Zhang等人[4]提出了基于生成对抗网络的跨语言词典抽取方法;Hoshen等人[5]提出了基于迭代最近点(ICP)算法的无监督翻译词典获取方法;Aldarmaki等人[6]提出了一种不需要线性变换的映射方法来获得初始化词典。然而现有工作大都先在单语语料上获得词向量,再将词向量空间对齐。本文提出了加入反馈机制重新训练词向量的新思路:先利用无监督方法得到双语词典,再借助词典利用单词替换的方式重新训练词向量。这种方法使得词向量在保持单语特性的同时具有更好的跨语言特性。
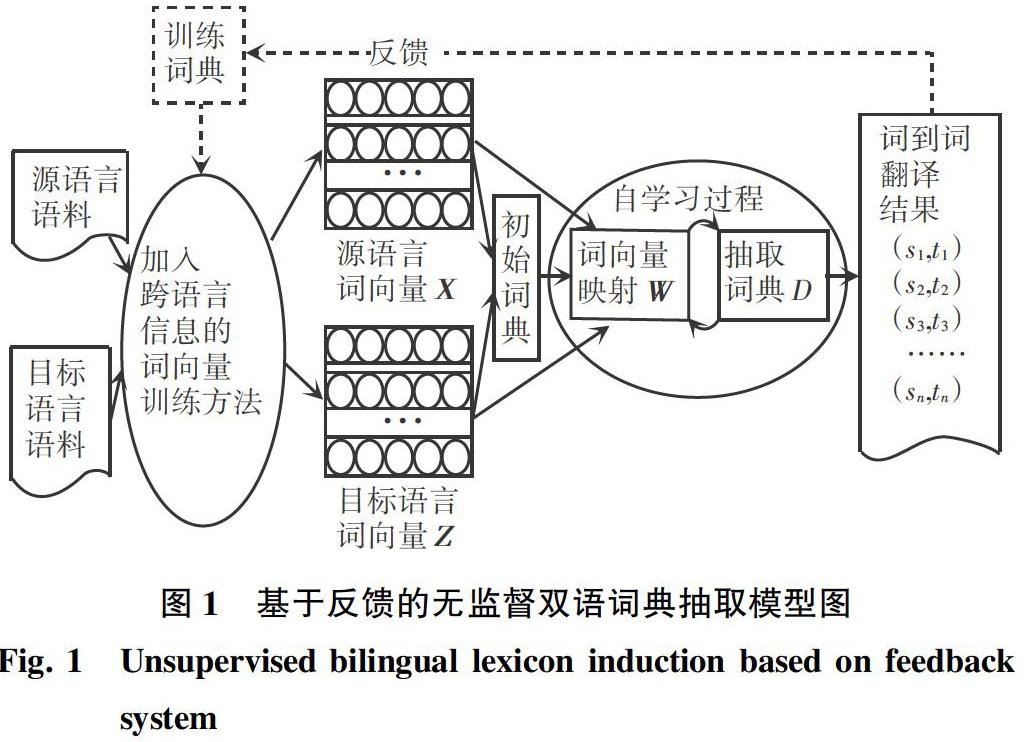
1 具有反馈机制的无监督跨语言词典抽取模型
本课题按照Conneau等人基于自学习的模式(Vecmap) [7]来进行研究。其过程主要分为:初始词典的选取、迭代的自学习过程。其中,自学习过程是映射矩阵的求解和双语词典的更新两步骤反复迭代直至收敛。在此基础上,本文加入反馈机制,用得到的词典重新训练词向量,整个模型框架如图1所示。
vecmap认为2种语言的向量空间严格满足同构性假设,使用正交变换来对齐2种语言的词向量空间。但单独训练得到的词向量并不能完全使正交变换来进行对齐。为使词向量具有更好的几何相似性,项目加入反馈机制,利用得到的翻译词典再重新训练具有更好跨语言特性的词向量,从而提高准确率。
2 基于替换的共训练方法
共训练模型的输入为2种语言的单语语料和无监督反馈得到的训练词典,输出为2种语言的具有跨语言特性的词向量。由于无监督方法得到的翻译结果并不是完全正確的,则要从中筛选出可能作为训练指导的翻译词对作为训练词典。具体地,需要确定翻译词表中选取哪些词作为词条以及每个词条的候选翻译个数。若只取最可能的一个作为翻译,反馈过程就没有意义;若候选词太多,会使训练变得困难,也会增加时间复杂度。本文评估了经自学习过程映射后词向量翻译的top-k准确率来确定候选词表的大小,并且比较了按照频率和置信度两种标准来筛选词条对结果的影响,经过筛选得到的词条加入训练词典指导下一轮词向量的共训练过程。
本文的共训练方法在word2vec中的CBOW模型[8]基础上加入跨语言信息。在训练词典的指导下,模型得到的词向量保持单语特性的同时要有很好的跨语言特性,即互为翻译的词所对应的词向量在空间中应该彼此接近。对于单语词向量而言,近义词或相关词由于上下文相似,训练后在空间中彼此接近。因此,本文提出基于替换的共训练方法:在语料中将训练词典中互为翻译的词按照一定概率进行替换,如此使两者就有了相同的上下文,便可以得到较为接近的词向量。例如,在翻译词典中“吃”对应的翻译为eat ,在训练语料中句子“你喜欢吃苹果吗”时,中文单词“吃”和英文单词eat 基于二者在词表中互为翻译的确信度以一定概率用同样的上下文进行训练。为了进一步融合双语语料,在训练过程中按照翻译的确信度以一定概率替换上下文。如图2所示。
由于篩选出的词典不能保证其中的词条一一对应,即一个源语言的词可能有若干个目标语言的词成为其候选翻译。本次研究在训练过程中根据词向量当前值为每一个词选出一个最可能的候选翻译,这些候选翻译实际上就组成了一个一对一的翻译集合。再利用这个确定的翻译来指导词向量的更新,该过程其实是一个EM算法:要求得word2vec的参数θ(包括词向量U和上下文向量V),随机初始化后,利用当前词向量得到确定的词典,再利用词典更新词向量,如此迭代直至收敛。EM算法具体如下:
3 实验
关于候选词大小的实验,本文在中英维基百科语料上用CBOW模型分别训练2种语言,再利用vecmap将2组词向量映射到同一空间,对于vecmap得到的映射后的词向量进行top-k准确率评估。分别采用最近邻(Nearest Neighbor, NN)和CSLS(Cross Domain Similarity Local Scaling)两种距离度量方式计算准确率。结果如图3所示。可以看出,随着词表数目的增加,准确率的增长越来越缓慢,本文后续实验使用准确率曲线拐点附近的值(5~10)作为候选词表大小设置。
利用替换方法进行无监督双语词典抽取的结果见表1。vecmap给出的实验结果在中英双语词典抽取上,CSLS准确率可以达到50.13,并以此作为基线。从表1可以看出,按照确信度的方法确定训练词典,在各个参数设置下CSLS准确率基本都超过了基线模型。并且在候选词个数为5时效果最好。此外,直接对基于替换的Bi-CBOW得到的词向量进行评价(表1中no_vecmap准确率)也有较高的准确率,说明这种方法得到的词向量已经具有了较好的跨语言特性。
表1中,向量维度300,负采样数25,迭代15轮。dic为候选词个数,fre为频率最高词数,size为词典大小。
4 结束语
针对分别训练的单语词向量不能很好地满足同
构性假设这一问题,本文提出了基于替换方法的双语共训练模型,通过反馈机制,将无监督方法得到的词典用于共训练过程,使得词向量具有较好的跨语言特性。按照确信度的标准选取词表虽然有着很高的准确率,但词表中依然存在着大量的数字和虚词等人类无法理解的翻译对,并且这类词往往会翻译为相同的目标词加重枢纽点问题(hub-ness problem)。因此下一步的研究重点是如何更好地解决枢纽点问题,进一步提高准确率。
参考文献
[1] ZOU W Y, SOCHER R, CER D M, et al. Bilingual word embeddings for phrase-based machine translation[C]// Proceedings of EMNLP. Seattle, Washington, USA:
dblp, 2013:1393-1398.
[2] BHATTARAI B, KLEMENTIEV A, TITOV I. Inducing crosslingual distributed representations of Words[C]// Proceedings of COLING 2012. Mumbai, India:ACL,2012:1459-1474.
[3] XU Kui, WAN Xiaojun . Towards a universal sentiment classifier in multiple languages[C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen, Denmark:ACL,2017:511-520.
[4] ZHANG Meng, LIU Yang, LUAN Huanbo, et al. Adversarial training for unsupervised bilingual lexicon induction[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1:
Long Papers). Vancouver, Canada:
Association for Computational Linguistics,2017:1959-1970.
[5] HOSHEN Y, WOLF L . Non-adversarial unsupervised word translation[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium:ACL,2018:469-478.
[6] ALDARMAKI H, MOHAN M, DIAB M. Unsupervised word mapping using structural similarities in monolingual embeddings[J]. Transactions of the Association for Computational Linguistics, 2018, 6:
185-196.
[7] CONNEAU A, LAMPLE G, RANZATO M, et al. Word translation without parallel data[J]. CoRR, abs/1710.04087,2017.
[8] KAICHEN T M, CORRADO G,DEAN J. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.